논문리뷰/기후
[논문리뷰] A Long Short-Term Memory (LSTM) Network forHourly Estimation of PM 2.5 Concentration in Two Cities of South Korea(2020)
- -
1시간 뒤 PM2.5 농도 예측, 2개 도시에서 수행.
Objective
- PM 2.5과 상관관계를 가지는 변수(feature) 분석
- 기상 변수: 온도, 풍향, 상대습도, surface roughness, planetary boundary layer, 강수량
- 오염 농도: PM10, CO, NO2, SO2, O3
- 오염 농도 변수는 각 지점에서 측정될 수 있고, CMAQ 모델로 예측할 수 있다. CMAQ 모델로 예측한 변수(elemental carbon, 암모니움, 질산염, 기타 미세 오염 물질 농도)를 합쳐서 적용했을 때, 모델의 성능 향상됨.
- 6개의 sota ML 모델을 적용해 성능을 서로 비교. 결론적으로 LSTM 모델이 가장 좋음.
- tree-based ML model: XGBoost, LightGBM
- DL model: LSTM, GRU, CNN-LSTM, BiLSTM
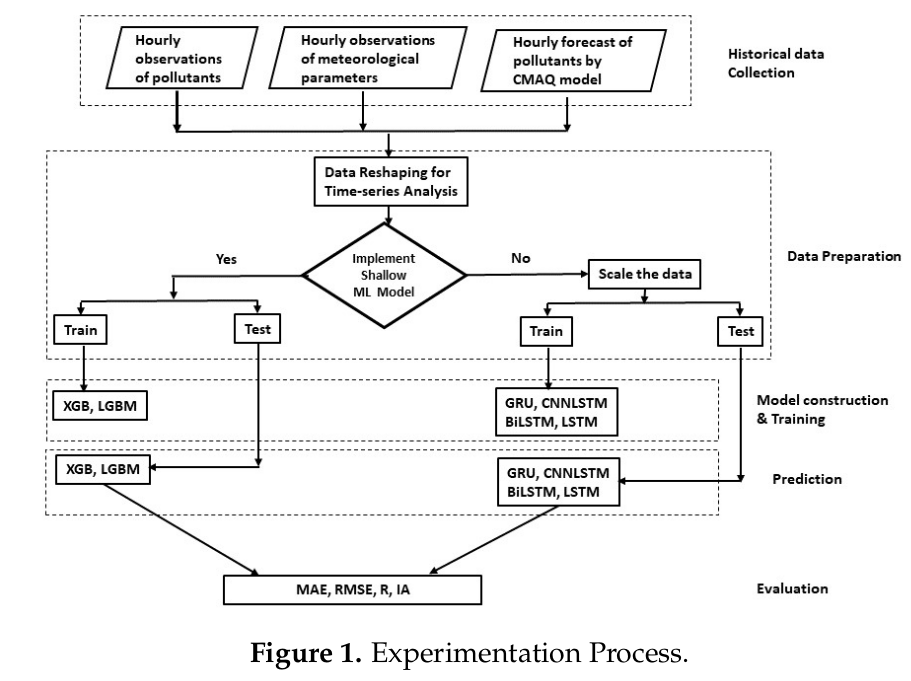
Data processing
- 시기: 2016년 1월 1일 ~ 12월 31일, 시간 단위.
- 장소: 서울과 광주에서 각각 4개 지점의 데이터 사용. 평가 시 각 지점의 값을 평균 취함.
- 데이터 구성
- 총 데이터 수:8727개(9:1 비율로 1~11월은 train, 12월을 test). 결측치는 linear interpolation으로 보완.
- 관측 정보: 기상 변수, 오염 공기 농도
- 6개 오염 농도: PM10, PM2.5, 이산화황 SO2, 이산화질소 NO2, 오존 O3, 일산화탄소 CO
- 6개 기상 변수: 기온, 풍속, 상대습도, surface roughness, planetary boundary layer, 강수량
- 예측값: 4개 오염원에 대해 CMAQ로 예측한 것. elemental carbon, nitrate, and ammonium은 PM2.5와 큰 상관관계를 갖는데 이에 대한 관측 데이터가 없음.
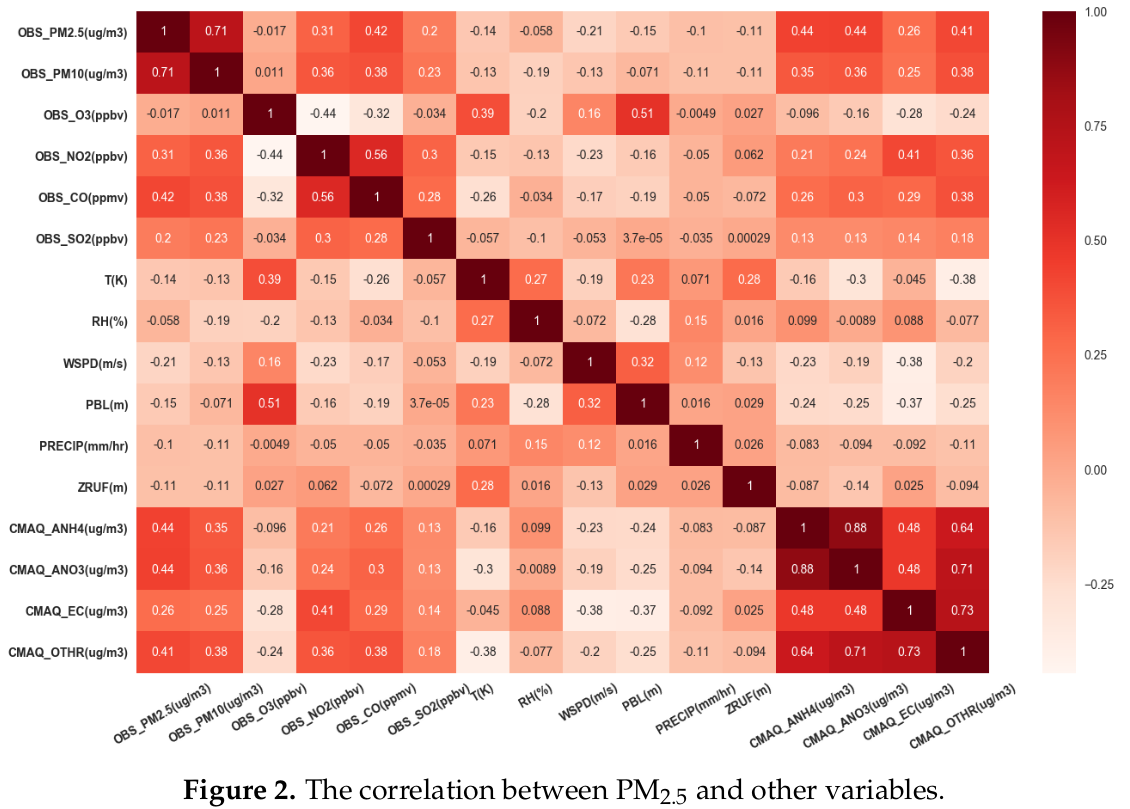
다음 순서로 PM2.5와 상관관계가 가장 높음.
PM 10 > C_NH4 = C_NO3 > CO > C_OTHERS > NO2 > C_EC > SO2
Training
t+1의 PM2.5를 예측하기 위해 t-23~t의 데이터를 학습. MAE, RMSE, R, IA로 평가.
- RNN
- GRU, LSTM, BiLSTM을 적용. RNN layer를 2개(hidden nodes:70)에 Dense layer 연결한 구조.
- RNN 2번째 layer 이후에 20%의 dropout 적용
- CNN-LSTM
- Conv1D 32, kernel size 3, stride 1
- maxpooling layer: pool size 3
- dropout 30%
- 공통적 parameter
- lr = 0.0001, loss function = MAE, optimizer: RMSprop, early stopping, batch size 32, activation: ReLU
Result
feature는 총 3가지로, Fp: 오염 농도, Fm: 기상 변수, Fc: CMAQ.
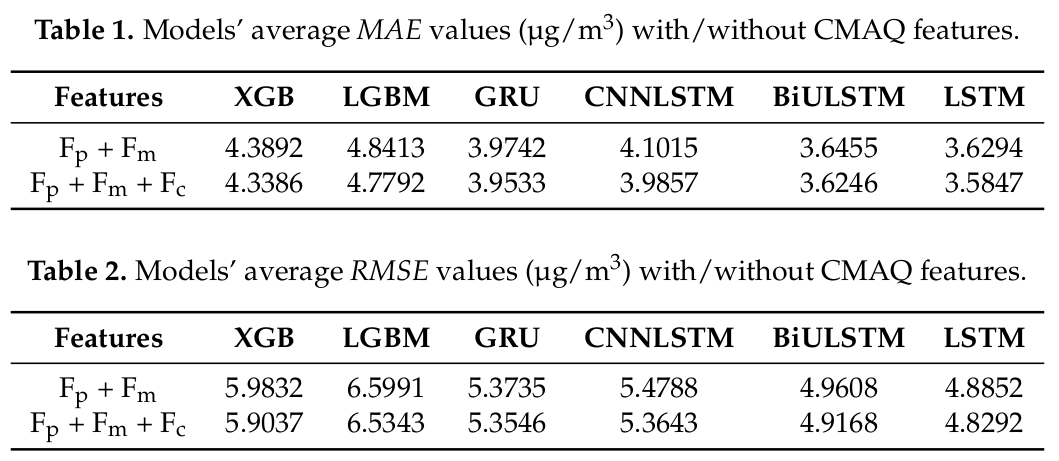
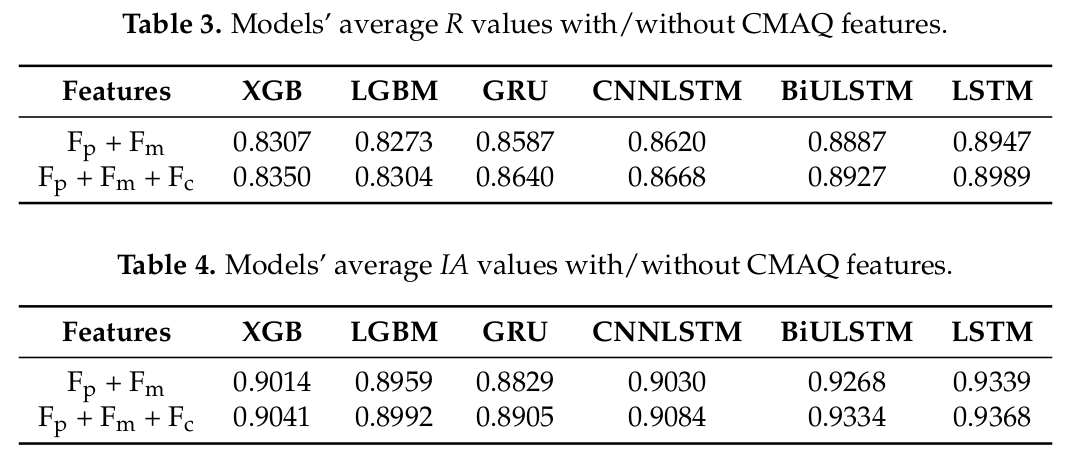
전체적으로 CMAQ를 사용했을 때 더 좋긴 하지만 너무 근소하게 좋음. 단순히 LSTM을 적용했을 때 가장 좋음.
보완점
- 데이터 부족: 1년밖에 적용 안 함.
- 1시간 뒤의 수치를 예측. 이후에 24시간 후 혹은 72시간 후 같은 장기 예측을 수행.
의문점
- 상관관계를 학습에 어떻게 반영했나? 반영 안 할 거면 왜 상관관계 조사한 건가?
- 결측치 보완 시 linear interpolation이 얼마나 효율적이었나?
- data spilit이 9:1이라면서 11월까지는 TRAIN 12은 TEST면 11:1 아닌가?
- 변수 수집한 지점이 구체적으로 어디지? 기상 변수와 오염 정보를 동시에 측정하는 지점의 정보를 썼나? 아니면 최대한 가까운 지점을 고른 건가? 왜 이 지점을 고른건가?
- input의 크기가 24(시간)*변수 수 인가?
- 풍향은 왜 사용 안 했나?
해볼 것
- 관측 지점의 변수에 영향을 많이 받는지 그 지점과 많이 떨어진 지점의 변수의 영향을 많이 받는지에 대한 지수, 계수를 개발할 필요 있음.
'논문리뷰 > 기후' 카테고리의 다른 글
Contents
소중한 공감 감사합니다